本文档主要介绍如何使用 U-Net 进行图像分割训练,以陶瓷片裂痕为例。
U-Net 训练手册
论文地址: https://arxiv.org/abs/1505.04597
代码地址: https://github.com/zhixuhao/unet
1. 网络结构
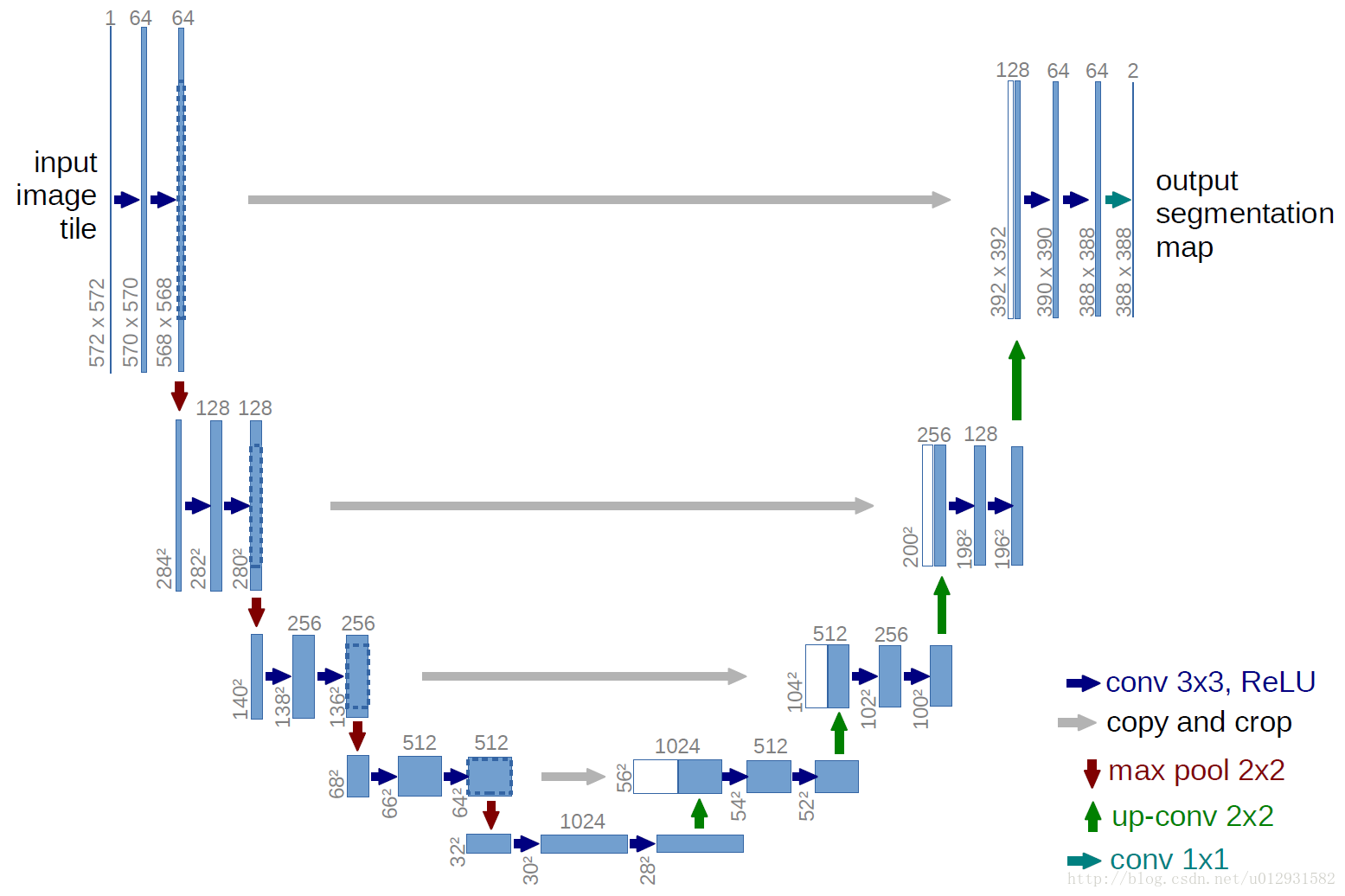
U-Net
是一种全卷积神经网络,其输入和输出均为图像,不包含全连接层。网络结构特点如下:
* 较浅的高分辨率层:用于解决像素精确定位的问题。 *
较深的层:用于解决像素分类的问题。
2. 环境配置
请按照以下步骤配置您的环境:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
conda create -n u-net python=3.5
conda activate u-net
pip install tensorflow-gpu==1.2.1
pip install keras==2.0.6
pip install scikit-image
conda install numpy
conda install h5py
git clone https://github.com/zhixuhao/unet.git
|
3. 项目文件结构
项目的建议文件结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| unet/
├── data/
│ └── mydata/ # 存放自定义数据集
│ ├── train/
│ │ ├── image/ # 存放训练图片 (例如: x.png)
│ │ └── label/ # 存放对应的标注图片 (例如: x.png)
│ └── test/ # 存放测试图片 (例如: y.png)
├── img/ # 存放测试样例图片和U-Net网络结构图
├── tools/ # 存放数据预处理脚本 (例如: 1_json_to_label.py, 2_tran_unet.py)
├── data.py # 数据加载和预处理脚本
├── main.py # 主训练脚本
├── model.py # U-Net 模型定义文件
├── trainUnet.ipynb # Jupyter Notebook 版本的 U-Net (可选)
└── unet_TCP.hdf5 # 训练得到的模型权重文件 (示例名称)
|
重要提示: * 在 data/mydata/train/
目录下,image 和 label
文件夹中的图片文件名必须一一对应。
4.
制作自定义数据集(以陶瓷片缺陷为例)
4.1. 安装 LabelMe
LabelMe 是一个图像标注工具,用于创建分割任务的标签。
1
2
3
|
conda install pyqt
pip install labelme==3.16.7
|
4.2. 使用 LabelMe进行图像标注
- 在 Conda 命令行中启动 LabelMe:
- 打开图像并进行标注(例如,勾勒出缺陷区域)。

- 标注完成后,点击 “Save”
保存。这会在原始图片所在的路径下生成一个同名的
.json
文件,其中包含了标注信息。
4.3. 批量转换 JSON 文件为
U-Net 数据集格式
以下 Python 脚本 (1_json_to_label.py) 用于将 LabelMe
生成的 .json 文件批量转换为 U-Net
训练所需的图像和标签图片。该脚本改编自 labelme 包内的
json_to_dataset.py。
脚本 1_json_to_label.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| import argparse
import json
import os
import os.path as osp
import numpy as np
import PIL.Image
from skimage import io
from labelme import utils
def main():
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-io', '--img_out_dir')
parser.add_argument('-lo', '--label_out_dir')
args = parser.parse_args()
json_file = args.json_file
img_out_dir = args.img_out_dir
label_out_dir = args.label_out_dir
list = os.listdir(json_file)
for i in range(0, len(list)):
path = os.path.join(json_file, list[i])
filename = list[i][:-5]
if os.path.isfile(path):
data = json.load(open(path))
img = utils.image.img_b64_to_arr(data['imageData'])
lbl, lbl_names = utils.shape.labelme_shapes_to_label(img.shape, data['shapes'])
PIL.Image.fromarray(img).save(osp.join(img_out_dir, '{}.png'.format(filename)))
utils.lblsave(osp.join(label_out_dir, '{}.png'.format(filename)), lbl)
if __name__ == '__main__':
main()
|
执行脚本:
1
| python 1_json_to_label.py <存放json文件的路径> -io <原始图片输出路径> -lo <标签图片输出路径>
|
此脚本会将原始图片保存到 -io
指定的目录,并将生成的标签图片(通常是黑底,标注区域为白色或特定类别颜色)保存到
-lo 指定的目录。确保输出的图片名与原始图片名一致。
4.4.
图像预处理:灰度转换、尺寸调整和标签二值化
以下 Python 脚本 (2_tran_unet.py)
用于对图像和标签进行预处理,以符合 U-Net 的输入要求。
脚本 2_tran_unet.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| import os
import cv2
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('-ip','--image_path')
parser.add_argument('-lp','--label_path')
args = parser.parse_args()
image_path = args.image_path
label_path = args.label_path
def image(image_path):
filenames = os.listdir(image_path)
for filename in filenames:
img = cv2.imread(os.path.join(image_path,filename), 0)
img = cv2.resize(img, (512, 512))
cv2.imwrite(os.path.join(image_path, filename), img)
print("successful img conversion!")
def label(label_path):
filenames = os.listdir(label_path)
for filename in filenames:
img = cv2.imread(os.path.join(label_path,filename), 0)
img = cv2.resize(img, (512, 512))
binary = cv2.threshold(img, 0, 255, cv2.THRESH_OTSU)[1]
cv2.imwrite(os.path.join(label_path, filename), binary)
print("successful label conversion!")
if __name__ == '__main__':
image(image_path)
label(label_path)
|
执行脚本:
1
| python 2_tran_unet.py -ip <原始图片路径> -lp <标签图片路径>
|
经过此脚本处理后,将得到指定大小(例如
512x512)、灰度格式的原始图像,以及对应大小、标签区域为白色的二值化标签图像。
5. 修改主训练文件
main.py
1
2
3
4
5
6
7
8
9
|
myGene = trainGenerator(2,'data/TCP/train','image','label',data_gen_args,save_to_dir = None)
model = unet()
model_checkpoint = ModelCheckpoint('unet_TCP.hdf5', monitor='loss',verbose=1, save_best_only=True)
model.fit_generator(myGene,steps_per_epoch=56,epochs=10,callbacks=[model_checkpoint])
|
关于 model.py
的潜在修改
根据原作者博文 (https://blog.csdn.net/u012931582/article/details/70215756)
的评论,有时需要对 model.py
中的网络结构进行微调,以避免输出结果一片灰的问题。具体地,可能需要注释掉或修改最后一层卷积:
1
| conv9 = Conv2D(2, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
|
注意: “一片灰”
的问题也可能是由于测试时输入的图像不是灰度图,或者数据预处理不当导致的。请逐一排查。
6. 训练和测试
完成上述配置和修改后,执行以下命令开始训练:
训练过程和结果示例如下:

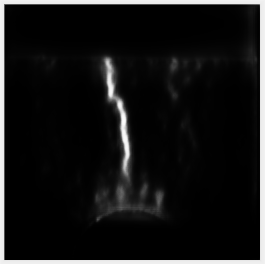
7. 其他说明
- 输入输出尺寸差异: 您可能会发现测试的输出图像尺寸是
256x256,而您的输入图像是 512x512。这通常是因为在
data.py
或 model.py 中,输入图像被统一调整 (resize)
到了模型预设的输入尺寸(例如
256x256)。请检查相关代码以确认具体行为。
- 调整学习率:
如果训练效果不佳,可以尝试适当降低学习率。学习率的调整通常在模型编译(
model.compile(...))时通过优化器参数设置,例如:
1
2
3
|
model.compile(optimizer=Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy'])
|
lr=1e-4 中的 1e-4
调整为一个更小的值,如 1e-5。